Architecture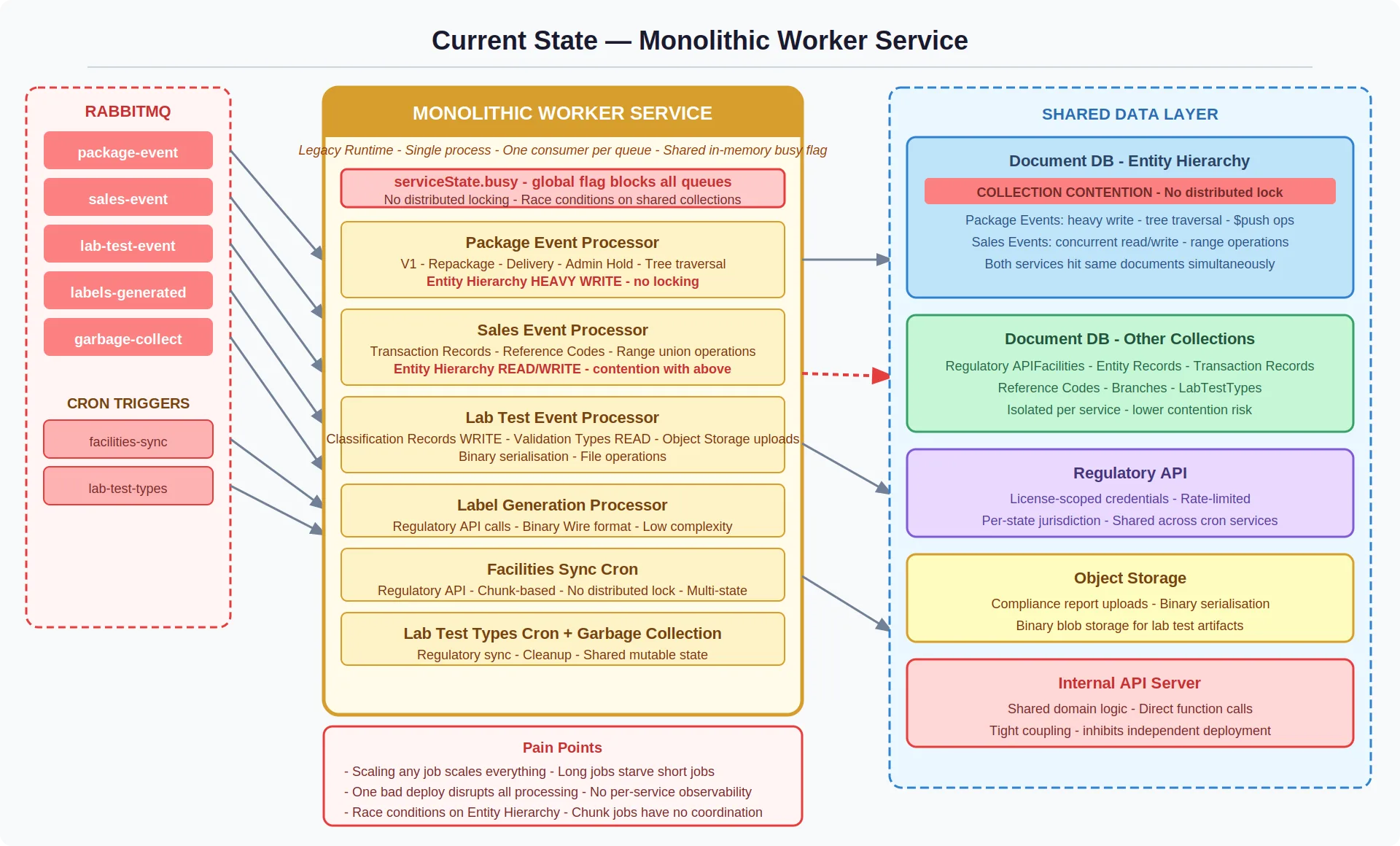
Architecture
From Busy Flag to Service Boundaries: Scaling a Monolithic Worker with Strangler Fig
A monolithic background worker processing compliance-critical events across six domains hit its scaling wall — but the real challenge wasn't technical. It was building the organizational confidence to decompose a system that couldn't go down, one boundary at a time.
3–5 min read
Key Tradeoffs
- Operational complexity for independent failure domains. One deployment becomes five, but a bad release in one domain no longer takes down the other four.
- Redis dependency for safe horizontal scaling. The system gains distributed locking and coordination, but adds a new infrastructure component that itself must be highly available.
- Shadow run duration for cutover confidence. Weeks of parallel processing before the highest-risk service goes live delays the timeline, but eliminates the chance of silent data corruption.
- Strangler Fig pace for rollback safety. One phase at a time is slower than a big-bang migration, but every phase has a clean path back to the monolith if something breaks.
- Shared NuGet contracts for consistency. A common message contract package keeps services aligned, but a breaking schema change now requires coordinated releases across consumers.
What happened
The platform's background processing ran through a single monolithic worker service — six distinct event-driven workloads sharing one process, one deployment pipeline, and one in-memory busy flag that enforced sequential message processing.
This was a deliberate early-stage tradeoff. One service meant one thing to deploy, one thing to monitor, and minimal infrastructure overhead. It worked — until it didn't.
The scaling ceiling surfaced through three business-visible symptoms. Customers experienced processing delays during high-volume periods because long-running ingestion batches blocked every other job type in the queue. The operations team couldn't deploy a fix to one domain without risking all six. And the engineering team identified a data integrity risk — two high-throughput processors writing to the same database collection with no coordination, a race condition masked by the single-process constraint that would become catastrophic the moment we tried to scale horizontally.
Decision Point
This architecture had become a constraint on the business, not just on the engineering team. We couldn't scale capacity for one workload without scaling everything. We couldn't deploy with confidence. And we couldn't isolate failures — a problem in cleanup processing was indistinguishable from the primary data pipeline without manually reading raw logs.
How it was addressed
The first leadership decision was framing the problem correctly. This wasn't a refactoring exercise — it was a risk mitigation investment. The system processed compliance-critical data on strict SLAs. The question wasn't whether to decompose, but how to do it without introducing more risk than we were retiring.
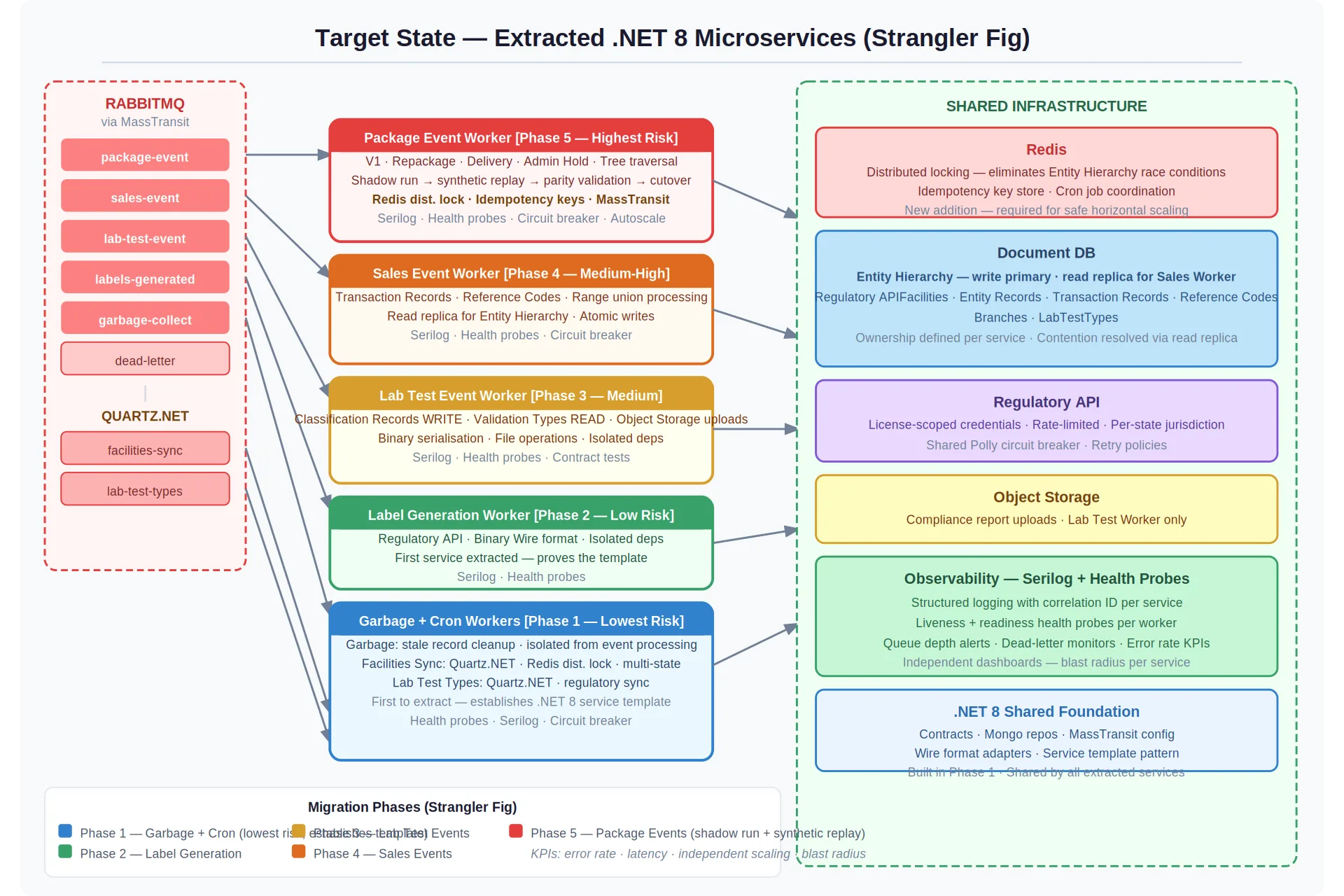
We chose the Strangler Fig pattern — the monolithic worker stays live throughout, with traffic routed to new services one event boundary at a time. Every phase has an explicit rollback path. No big-bang cutover, no downtime windows.
Sequence by risk, not by convenience. It would have been tempting to start with the most painful workload. Instead, we started with the lowest-risk services — scheduled syncs and cleanup tasks. This validated the new service template, deployment pipeline, and autoscaling in production before anything customer-facing was touched. The team built confidence through small, reversible wins.
Resolve shared state before splitting ownership. The database collection contention was the single highest-risk item. Extracting services without solving the coordination problem first would have turned a single-process race condition into a distributed one. We required Redis distributed locking and read replica routing to be validated in production before the dependent service could be extracted. This blocked the timeline but protected the migration's integrity.
Validate the hardest migration with evidence, not assumptions. The primary ingestion worker decoded a binary payload format tightly coupled to the legacy runtime. A mismatch would silently corrupt audit data. We mandated a shadow run — the new service processing in parallel with the legacy worker, comparing output byte-for-byte, with cutover gated on 100% parity. This added weeks but eliminated the highest-consequence risk.